使用 RSA 理解夸张¶
"My new kettle cost a million dollars."
夸张——使用夸大的言语来传达强烈观点——是语言常见的一种非字面用法。然而,在最简单的 RSA 模型下,语言的非字面用法是不可能的。Kao 等人提出,可以添加两种成分来使 RSA 能够捕捉夸张。首先,说话者传达并听话者推断的状态应包括情感维度。其次,说话者只打算传达与特定主题相关的信息,例如“这有多贵?”或“我对价格有什么感觉?”;因此,语用听话者会联合推断这个主题和状态。
[1]:
#first some imports
import torch
torch.set_default_dtype(torch.float64) # double precision for numerical stability
import collections
import argparse
import matplotlib.pyplot as plt
import pyro
import pyro.distributions as dist
import pyro.poutine as poutine
from search_inference import HashingMarginal, memoize, Search
与简单的 RSA 示例一样,推断辅助工具 Marginal 接受一个未标准化的随机函数,通过使用 Search 构建执行轨迹的分布,并通过 HashingMarginal 构建返回值的边缘分布。
[2]:
def Marginal(fn):
return memoize(lambda *args: HashingMarginal(Search(fn).run(*args)))
本示例的域将是包含价格(例如茶壶的价格)和说话者情绪唤醒(说话者是否认为这个价格令人恼火地贵)的状态。此处的先验是根据实验数据调整的。
[3]:
State = collections.namedtuple("State", ["price", "arousal"])
def price_prior():
values = [50, 51, 500, 501, 1000, 1001, 5000, 5001, 10000, 10001]
probs = torch.tensor([0.4205, 0.3865, 0.0533, 0.0538, 0.0223, 0.0211, 0.0112, 0.0111, 0.0083, 0.0120])
ix = pyro.sample("price", dist.Categorical(probs=probs))
return values[ix]
def arousal_prior(price):
probs = {
50: 0.3173,
51: 0.3173,
500: 0.7920,
501: 0.7920,
1000: 0.8933,
1001: 0.8933,
5000: 0.9524,
5001: 0.9524,
10000: 0.9864,
10001: 0.9864
}
return pyro.sample("arousal", dist.Bernoulli(probs=probs[price])).item() == 1
def state_prior():
price = price_prior()
state = State(price=price, arousal=arousal_prior(price))
return state
现在我们定义一个只为字面听话者产生 相关 信息的 RSA 说话者版本。我们根据讨论中的问题 (QUD) 定义相关性——这可以被视为定义说话者当前的注意点或主题。
说话者在数学上定义为
为了将其实现为概率程序,我们从辅助函数 project 开始,它接受某个(离散)域上的分布和此域上的函数 qud。它使用 Marginal(作为 Python 装饰器)创建前推分布。说话者的相关信息随后只是关于此投影中状态的信息。
[4]:
@Marginal
def project(dist,qud):
v = pyro.sample("proj",dist)
return qud_fns[qud](v)
@Marginal
def literal_listener(utterance):
state=state_prior()
pyro.factor("literal_meaning", 0. if meaning(utterance, state.price) else -999999.)
return state
@Marginal
def speaker(state, qud):
alpha = 1.
qudValue = qud_fns[qud](state)
with poutine.scale(scale=torch.tensor(alpha)):
utterance = utterance_prior()
literal_marginal = literal_listener(utterance)
projected_literal = project(literal_marginal, qud)
pyro.sample("listener", projected_literal, obs=qudValue)
return utterance
可能的 QUD 捕捉了说话者可能关注价格、她的情感或这些的某种组合。我们假设 QUD 的先验是均匀的。
[5]:
#The QUD functions we consider:
qud_fns = {
"price": lambda state: State(price=state.price, arousal=None),
"arousal": lambda state: State(price=None, arousal=state.arousal),
"priceArousal": lambda state: State(price=state.price, arousal=state.arousal),
}
def qud_prior():
values = list(qud_fns.keys())
ix = pyro.sample("qud", dist.Categorical(probs=torch.ones(len(values)) / len(values)))
return values[ix]
现在我们指定话语的含义(标准数字词指称:“N”表示恰好 \(N\))和均匀的话语先验。
[6]:
def utterance_prior():
utterances = [50, 51, 500, 501, 1000, 1001, 5000, 5001, 10000, 10001]
ix = pyro.sample("utterance", dist.Categorical(probs=torch.ones(len(utterances)) / len(utterances)))
return utterances[ix]
def meaning(utterance, price):
return utterance == price
好的,让我们看看这位说话者会说什么数字词来表达不同的状态和 QUD。
[7]:
#silly plotting helper:
def plot_dist(d):
support = d.enumerate_support()
data = [d.log_prob(s).exp().item() for s in d.enumerate_support()]
names = support
ax = plt.subplot(111)
width=0.3
bins = list(map(lambda x: x-width/2,range(1,len(data)+1)))
ax.bar(bins,data,width=width)
ax.set_xticks(list(map(lambda x: x, range(1,len(data)+1))))
ax.set_xticklabels(names,rotation=45, rotation_mode="anchor", ha="right")
# plot_dist( speaker(State(price=50, arousal=False), "arousal") )
# plot_dist( speaker(State(price=50, arousal=True), "price") )
plot_dist( speaker(State(price=50, arousal=True), "arousal") )
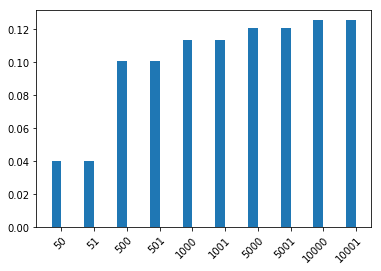
尝试上面的不同值!说话者何时会倾向于非字面话语?
最后,语用听话者不知道 QUD 是什么,因此会联合推断 QUD 和状态。
[8]:
@Marginal
def pragmatic_listener(utterance):
state = state_prior()
qud = qud_prior()
speaker_marginal = speaker(state, qud)
pyro.sample("speaker", speaker_marginal, obs=utterance)
return state
这位听话者如何解释说出的价格“10,000”?一方面,这是一个先验上极不可能的价格,另一方面,如果它是真的,它会伴随强烈的唤醒。总而言之,这成为一个貌似合理的 夸张 话语
[9]:
plot_dist( pragmatic_listener(10000) )
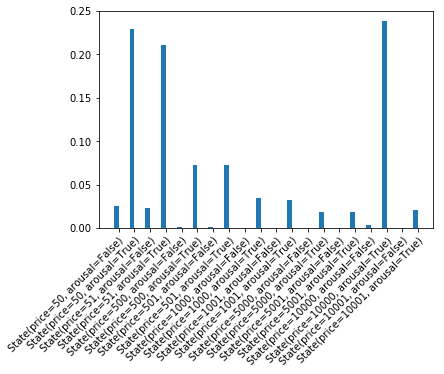
语用光环¶
“它花费了五十美元”通常被解释为花费 大约 50 美元——可能是 51 美元;然而“它花费了五十一美元”则被解释为 51 美元,肯定不是 50 美元。这种非对称的不精确性常被称为语用光环或语用松弛。
我们可以扩展夸张模型来捕捉数字的这种额外非字面用法,方法是包含将附近数字折叠的 QUD 函数,并假设整数稍微更可能(因为它们更容易说出口)。
[10]:
#A helper to round a number to the nearest ten:
def approx(x, b=None):
if b is None:
b = 10.
div = float(x)/b
rounded = int(div) + 1 if div - float(int(div)) >= 0.5 else int(div)
return int(b) * rounded
#The QUD functions we consider:
qud_fns = {
"price": lambda state: State(price=state.price, arousal=None),
"arousal": lambda state: State(price=None, arousal=state.arousal),
"priceArousal": lambda state: State(price=state.price, arousal=state.arousal),
"approxPrice": lambda state: State(price=approx(state.price), arousal=None),
"approxPriceArousal": lambda state: State(price=approx(state.price), arousal=state.arousal),
}
def qud_prior():
values = list(qud_fns.keys())
ix = pyro.sample("qud", dist.Categorical(probs=torch.ones(len(values)) / len(values)))
return values[ix]
def utterance_cost(numberUtt):
preciseNumberCost = 10.
return 0. if approx(numberUtt) == numberUtt else preciseNumberCost
def utterance_prior():
utterances = [50, 51, 500, 501, 1000, 1001, 5000, 5001, 10000, 10001]
utteranceLogits = -torch.tensor(list(map(utterance_cost, utterances)),
dtype=torch.float64)
ix = pyro.sample("utterance", dist.Categorical(logits=utteranceLogits))
return utterances[ix]
RSA 说话者和听话者的定义保持不变
[11]:
@Marginal
def literal_listener(utterance):
state=state_prior()
pyro.factor("literal_meaning", 0. if meaning(utterance, state.price) else -999999.)
return state
@Marginal
def speaker(state, qud):
alpha = 1.
qudValue = qud_fns[qud](state)
with poutine.scale(scale=torch.tensor(alpha)):
utterance = utterance_prior()
literal_marginal = literal_listener(utterance)
projected_literal = project(literal_marginal, qud)
pyro.sample("listener", projected_literal, obs=qudValue)
return utterance
@Marginal
def pragmatic_listener(utterance):
state = state_prior()
qud = qud_prior()
speaker_marginal = speaker(state, qud)
pyro.sample("speaker", speaker_marginal, obs=utterance)
return state
好的,让我们看看是否获得了所需的非对称松弛(我们在这里只关心解释的价格,因此我们将唤醒边缘化掉)。
[12]:
@Marginal
def pragmatic_listener_price_marginal(utterance):
return pyro.sample("pm", pragmatic_listener(utterance)).price
plot_dist(pragmatic_listener_price_marginal(50))
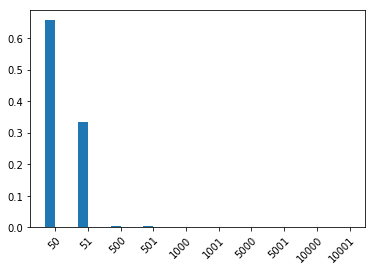
[13]:
plot_dist(pragmatic_listener_price_marginal(51))

反讽和更复杂的情感¶
在上述夸张模型中,我们假设了一种非常简单的情感模型:一个具有两个值(高唤醒和低唤醒)的单维度。实际的情感最好表示为一个二维空间,对应于效价和唤醒。Kao 和 Goodman (2015) 表明,将情感空间扩展到这两个维度会立即引入数字的一种新用法:言语反讽,其中对应于高唤醒、正效价状态的话语被用来传达高唤醒但负效价(或反之)。